技术问题
人群包创建后,系统什么时候开始处理?
人群包创建好后,DNA将对其实时处理。一般人群包2h左右可处理完成,lookalike人群包需7h左右处理完成。
PLUS的人群包同步几次?
每日1点、12点和17点启动同步任务。
人群包历史版本留存时间是多久?
答:三方问询人群包留存近30个历史版本数据(与天数无关),其他类型人群包仅留存近3个历史版本数据。
人群包失效后是真的删掉吗?
答:人群包失效后,会有7天的窗口期,7天后人群包数据真正删除。
人群包洞察报告和画像历史版本数据留存时间是多久?
答:人群包失效后7天删除人群洞察,自动更新若超过三个版本则会自动删除以前的历史版本。
三方问询接口的技术文档?
三方问询的问询接口API由第三方提供,不同的人群包,不同的业务逻辑使用到的技术文档都不一样。
三方问询的流程是什么?技术逻辑是什么?
当问询发起时,DNA首先将特定人群发至第三方(如支付宝)问询,支付宝会会对其进行验证是否符合要求,然后DNA再次将符合要求的人群发送至支付宝。若有2+次问询,则按照选定的问询频次以及问询时间继续对支付宝进行问询。
DNA的ID类型加密格式是什么?
IDFA采取明文形式;IMEI采用MD5加密。
数据MD5加密工具?
java实现MD5加密方法:
1、java自带jar工具MessageDigest实现
java.security.MessageDigest
2、spring自带的工具DigestUtils实现
org.springframework.util.DigestUtils
人群包需要JD/天猫前验后验怎么办?
前验:广告投放前的数据在京东/天猫的数据验证;
后验:广告投放后在京东/天猫数据校验。
可使用Notepad++对人群包进行文件拆分、编码转换等相关操作。
如何修改下载的人群包文件的编码格式为UTF8?
答案:下载文件编辑器Notepad++,另存为时选择编码格式UTF8.
如何知道下载的人群包文件的行数?
答案:用Excel打开查看行数;对于大文件可以用文件编辑器Notepad++打开查看行数;
下载的人群包文件如果需要打开,修改后缀、编码方式怎么办?
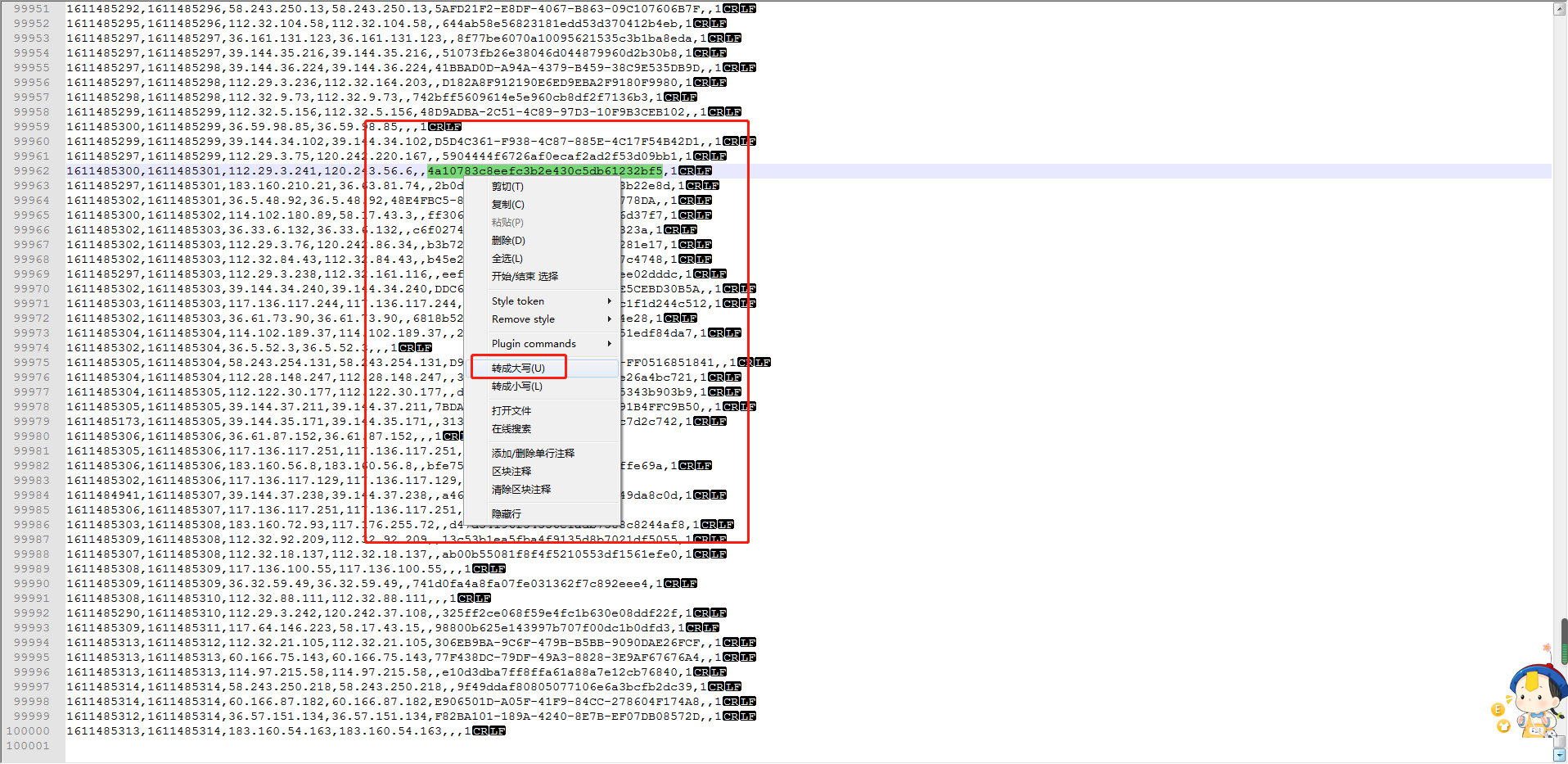
1、用notepad++打开txt或者csv文件,选中文件右键选择Edit with Notepad++打开。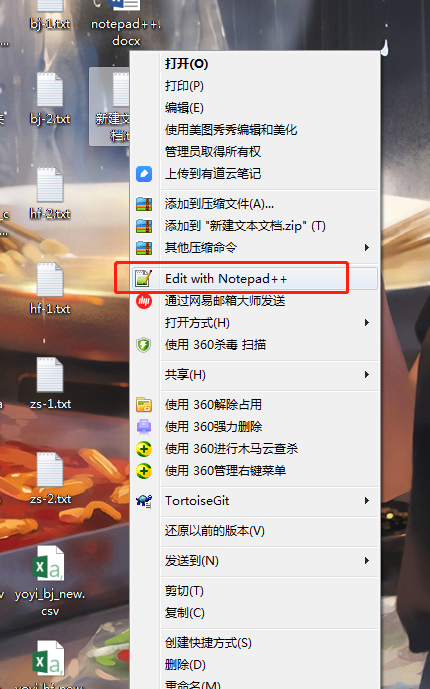
2.打开文件左侧是文件行数。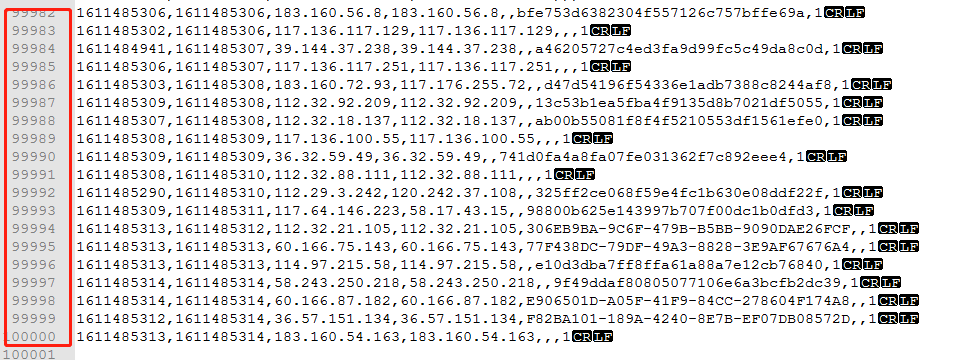
3.文件拆分,根据文件大小判断要拆分的文件个数和每个文件保留的行数,从目前文件剪切选中内容,粘贴到另一个txt或者csv文件。
4.打开文件,编码选项显示当前文件编码格式(蓝点选中项)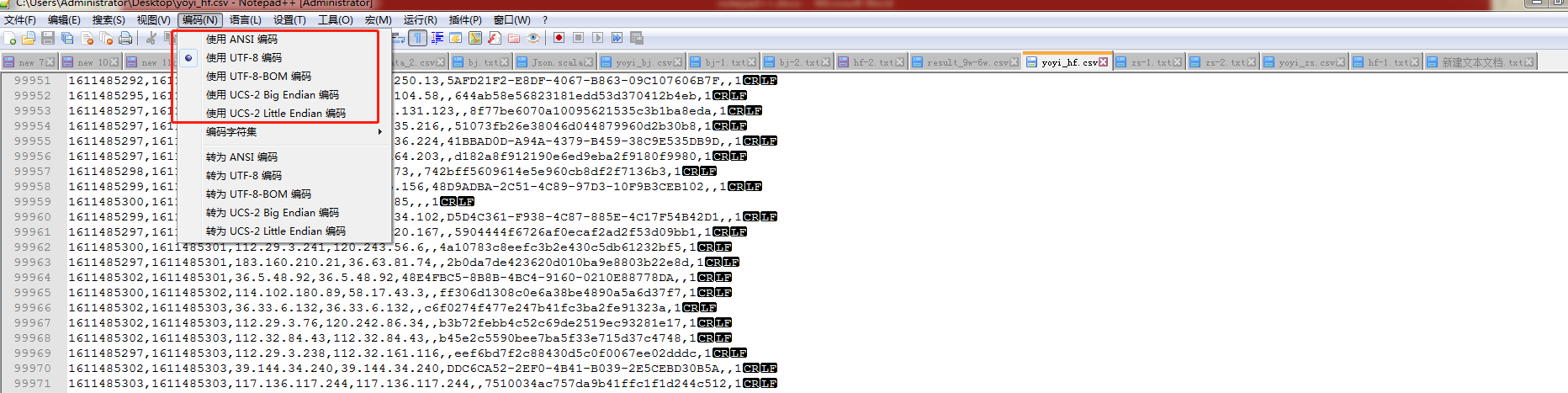
修改编码格式,可以ctrl+A全选文件内容,点击要转的编码项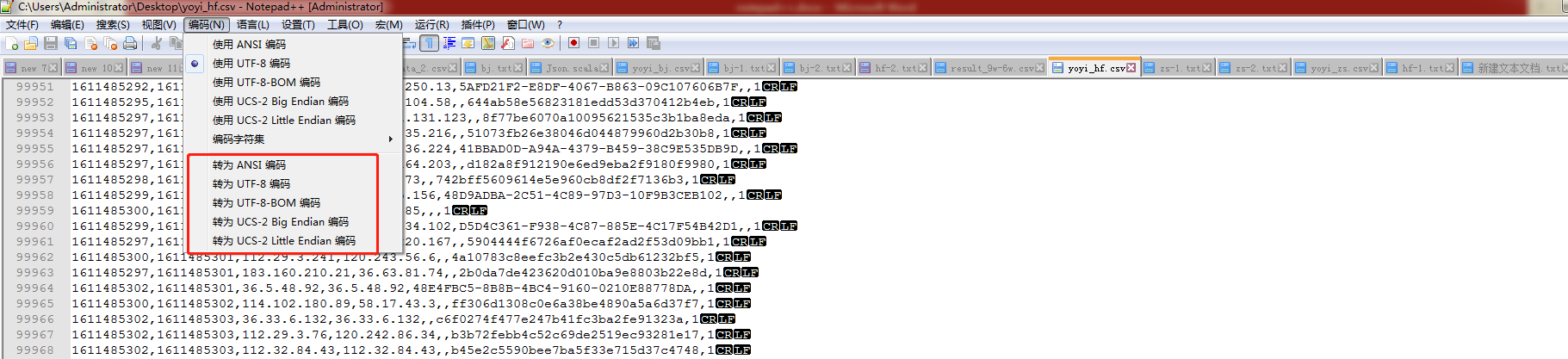
5.字符大小写转换,选中字符串邮件选择转大写或者转小写
如果客户需要上传YOYI ftp怎么办?
- 下载FileZilla客户端;(下载链接)
- FTP配置;
- 上传文件;
- 附:FileZilla使用教程:https://www.yiweihy.com/knowledge/used/215-ftp-filezilla.html
TGI数据源分为哪些类?
答案:分为数盟来源和yoyi来源两类。
引用数盟数据源有哪些方案?
方案一:
- 剔除数盟中存在的yoyi标签,需要与底层yoyi标签数据关联
- 数盟数据8亿与底层80亿标签数据关联,时间预估:500core,大概需要40min-60min
- 基于数盟数据生成gid数据
- 若关联gid数据:gid数据过大,存在时间性能问题,大概需要30min
- 若基于gid生成方式,单独生成gid数据同时关联跨屏,大概需要30min
方案二:
- 数盟数据与生成DNA数据关联,直接生成gid数据
- 优点:流程简单,时间更短,大约1h
- 缺点:无法剔除数盟中存在的yoyi标签
TGI计算流程是怎样的?
- 建立具有标签来源的统计存储表
- 统计数盟数据源的各层级标签数量
- 生成一份
- 统计人群包中各个层级标签数量
- 通过数据源的优先级进行TGI计算,通过高优先级计算的标签不再进入低优先级的标签TGI计算
TGI计算公式?
| 序号 | 计算方式 | 详细指标计算 | 计算所属范围 | 描述 |
|---|---|---|---|---|
| 1 | 人群包标签的占比/标签在DNA上的占比 | 人群包占比=人群包含有该标签的数量/人群中含有该标签所属维度的数量,标签在DNA上的占比=标签的数量/DNA上该标签所属维度的数量 | 同一个device的同级标签之间不具有互斥性 | 标签所属维度:指标签所属的大维度,如:媒体偏好、消费偏好等大类 |
| 2 | 人群包标签的占比/标签在DNA上的占比 | 人群包占比=人群包含有该标签的数量/人群含有该类型标签的数量,标签在DNA上的占比=标签的数量/该类型标签在DNA的总数量 | 同一个device的同级标签之间具有互斥性 | 该类型标签:指标签的父级标签,如:男的父级标签(类型标签)是性别 |
计算样例:
公式1:
| 标签名 | 人数 |
|---|---|
| 人群包中男 | 50 |
| 人群包中性别 | 110 |
| DNA中男 | 414678124 |
| DNA中性别 | 886391047 |
| 人群包中女 | 40 |
| 人群包中性别 | 110 |
| DNA中女 | 467503424 |
| DNA中性别 | 886391047 |
- 男的TGI:(50/110)/(414678124/886391047)=97.16
- 女的TGI:(40/110)/(467503424/886391047)=68.95
公式2:
| 标签名 | 人数 |
|---|---|
| 人群包中汽车 | 50 |
| 人群包中购物倾向 | 110 |
| DNA中汽车 | 109000284 |
| DNA中购物倾向 | 312732039 |
| 人群包中游戏 | 40 |
| 人群包中购物倾向 | 110 |
| DNA中游戏 | 88912303 |
| DNA中购物倾向 | 312732039 |
- 汽车的TGI:(50/110)/(109000284/312732039)=130.41
- 游戏的TGI:(40/110)/(88912303/312732039)=159.87